COM6523 System Evolution and Driving Forces Draft
How Have the System’s Size and Complexity Changed Over Time?
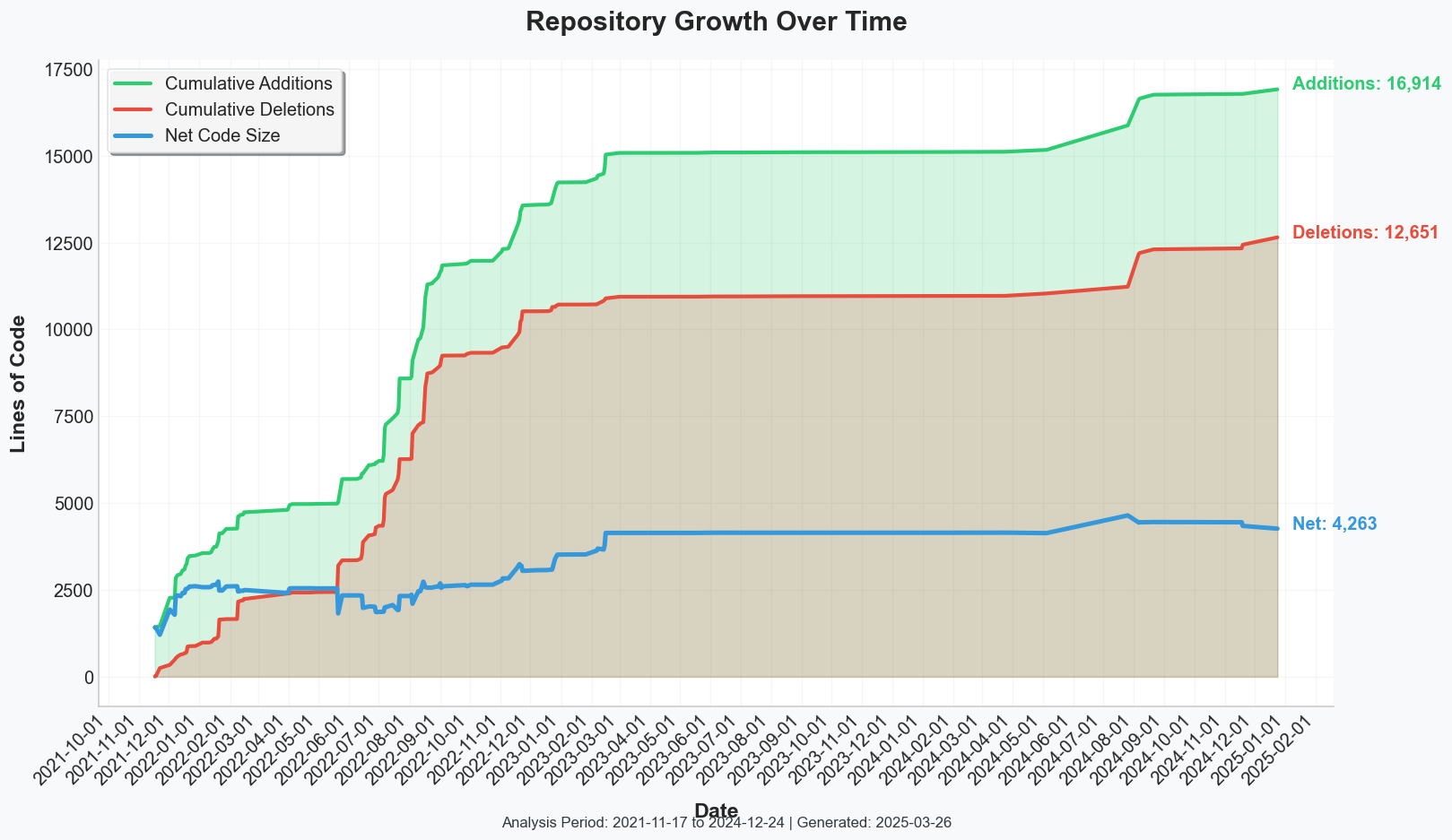 Deep-River, originally introduced as river-torch in late 2022, has experienced substantial growth through three distinct phases: initial release (v0.1.x), intensive feature expansion (v0.2.x), and eventual refinement and maturity (late 2024).
Deep-River, originally introduced as river-torch in late 2022, has experienced substantial growth through three distinct phases: initial release (v0.1.x), intensive feature expansion (v0.2.x), and eventual refinement and maturity (late 2024).
In the v0.1.x stage, the project already exhibited a modular architecture, clearly defining modules for classification, regression, anomaly detection, and utilities. These modules, along with rolling classes designed to manage incremental learning tasks, contributed early complexity by providing distinct logic to handle ever-evolving data streams.
Transitioning to Deep-River (v0.2.x) involved significant reorganization, setting the stage for notable feature expansion. Integrations of recurrent networks (LSTM-based models), multi-output regressors, and advanced autoencoder variants substantially increased both size and complexityEach new feature—whether for sequence learning, multi-target prediction, or enhanced rolling logic—introduced added complexity in the form of specialized layers, incremental updates, and revised adaptation strategies.
By late 2024, the project shifted toward refinement, with fewer major feature additions but more emphasis on polishing and minor enhancements, such as optional visualization tools and specialized anomaly modules. Continuous refactoring during this phase reduced redundancies from earlier rolling classes and anomaly pipelines, ensuring growth remained coherent and manageable.
The ongoing enhancement of test coverage reinforced system reliability, aligning closely with the project’s streaming learning foundation.
How Have the System’s Architecture, Design, and Functionality Changed Over Time?
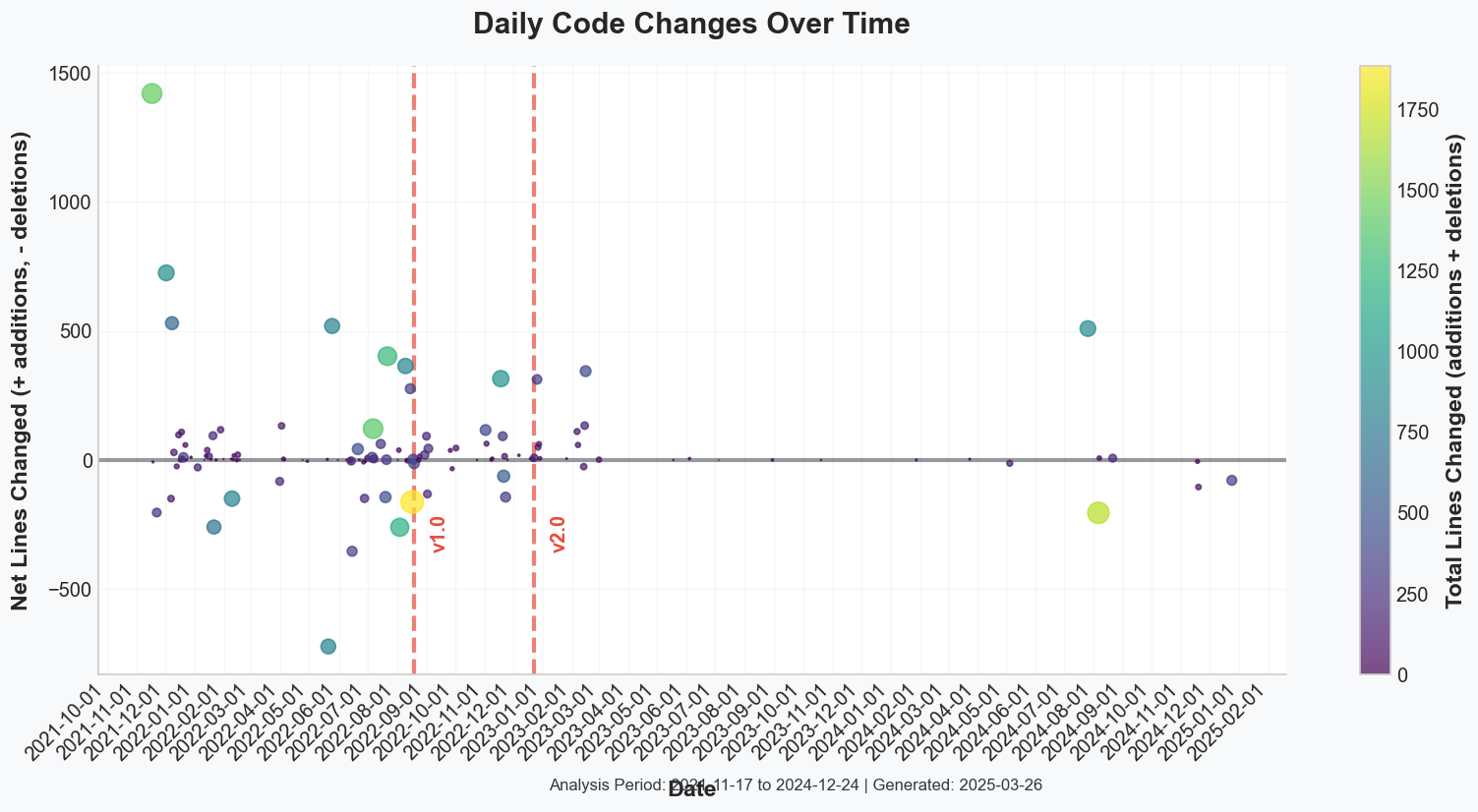 Deep-River’s architecture aligned closely with River’s modular and incremental learning philosophy, built around a central
Deep-River’s architecture aligned closely with River’s modular and incremental learning philosophy, built around a central DeepEstimator base class.
In the initial v0.1.x releases, the architecture supported essential online training scenarios, primarily through rolling variants capable of dynamically adjusting model weights. The adherence to River’s established interfaces (learn_one, predict_one, and score_one) ensured functional consistency across diverse tasks like classification, regression, and anomaly detection.
During the v0.2.x phase, alongside rebranding, architectural refinements included the consolidation of rolling class logic to eliminate duplication, introduction of LSTM frameworks for streaming sequence data, and enhancement of multi-output regression capabilities. Recurrent layers added complexity in maintaining hidden states, while multi-target regressors necessitated robust handling of multiple outputs. Additionally, specialized autoencoders were developed for improved anomaly detection.
By 2024, Deep-River’s design had reached a point of stability, manifesting a cohesive layout that balanced the need for versatility with the importance of maintainability. Another important design aspect involved handling new classes in classification tasks, ensuring that the network architecture could be updated incrementally without burdening the end user with low-level PyTorch details.(Deep River - Why handling New classes in classification)
Collectively, these evolutions preserved the original River-inspired streaming ethos, fortified by PyTorch’s dynamic computational graph, and resulted in a unified yet adaptable system well-suited for a wide spectrum of real-time learning problems.
What Factors Have Influenced the System’s Changes?
Multiple factors influenced Deep-River’s development, beginning with the foundational principles established by the original River team. Their experience directed early architectural decisions toward seamless integration of deep learning into streaming tasks, forming a clear developmental roadmap.
Preparation for publication and peer reviews, notably for the Journal of Open Source Software, emphasized clear code structure, comprehensive unit testing, and detailed documentation, thus balancing innovative expansion with maintainability.
Engagement with the open-source community through GitHub issues and feedback guided feature prioritization, highlighting the importance of smooth incremental updates and consistent performance evaluation.
Ultimately, Deep-River’s evolution reflects a strategic transformation from an initial prototype to a mature, robust framework, effectively combining PyTorch’s powerful deep learning functionalities with River’s efficient streaming data paradigm.